flynn.gg
Christopher Flynn
Machine Learning
Systems Architect,
PhD Mathematician
Projects
Open Source
Blog
Résumé
GitHub
Blog
OpenTelemetry and scikit-learn
2020-09-17 
 Photo by Yassine Khalfalli
Photo by Yassine Khalfalli
Opentelemetry is a relatively new observability specification encapsulating a set of APIs for distributed tracing, metrics, and logging. We’ve been experimenting a bit with the distributed tracing implementation recently on our platform which includes a python application for making machine learning predictions in real time.
Out of the box, the open source implementation supports auto-instrumentation of web frameworks, DBAPIs, and other common frameworks. For our use case, however, a large proportion of a request’s execution context exists in the machine learning model, and we wanted more visibility on those operations.
For libraries that are web frameworks or DBAPIs, instrumentation means patching specific points in code where application boundaries might exist. For a web framework like Django or Flask, instrumentation would likely involve patching methods of application that handle requests, creating tracing spans for each piece of middleware in the request handling lifecycle. For a DBAPI we would patch the functions which perform I/O operations against the database, to measure time spent executing queries.
Machine learning (ML) libraries, on the other hand, are a bit different. ML packages like scikit-learn typically consists of many independent functional components, implementing the same API, that can either be used on their own or composed together in a sequence generally referred to as a pipeline. Instrumenting the sklearn library would mean enumerating all of the components and patching each one of them.
This is particularly challenging since the sklearn package is still changing with transformers being added or deprecated regularly, meaning we would run into compatibility difficulties between different versions. If we opt instead for scanning every object in the library and selectively instrumenting BaseTransformer-derived classes, we might overinstrument by patching tree-based classifiers, for instance. At runtime we would end up with n_estimators-worth of spans, which we probably don’t want as it would add noise to visualizations and add unnecessary memory usage during execution. This could also lead to slower startup times.
We also acknowledge that scikit-learn is an extensible framework, meaning that end-users have the ability to create custom transformers and estimators which would be missed by the auto-instrumentation. We would also want the user to be able to instrument their own estimators as well.
Considering these ideas, we opt to instrument models explicitly rather than patching the library itself. In doing so, we are also cognizant of the fact that the components can be chained, composed, and inherited with one another.
The methods we are interested in measuring are the fit, transform, predict, and predict_proba methods, found on most BaseEstimator-derived objects. We also know that classes like Pipeline and FeatureUnion are containers for sequences of other transformers via the attributes steps and transformer_list, respectively. We also consider the fact that some classes wrap other estimators, for instance ensemble estimators like the RandomForestClassifier or MultiOutputRegressor.
This means that our code should iterate, recursively, through our model, handling these cases appropriately. Since sklearn is extensible, we also want to provide configuration options for custom estimators that may have similar implementations encapsulating other estimators. Here is what our instrumentor looks like:
import logging
from functools import wraps
from typing import TYPE_CHECKING
from typing import Sequence
from opentelemetry.trace import get_tracer
from sklearn.pipeline import FeatureUnion
from sklearn.pipeline import Pipeline
from .version import __version__
if TYPE_CHECKING:
from typing import Callable
from typing import Dict
from typing import List
from typing import Type
from sklearn.base import BaseEstimator
logger = logging.getLogger(__name__)
def implement_spans(func: "Callable", estimator_name: str):
"""Wrap the method call with a span.
Args:
func: A callable to be wrapped in a span
estimator_name: The name of the estimator class. We pass estimator name
here because there are some wrapped methods in Pipeline that don't
have ``__self__`` to access the class name.
Returns:
The passed function wrapped in a span.
"""
logger.debug("Instrumenting: %s.%s", estimator_name, func.__name__)
@wraps(func)
def wrapper(*args, **kwargs):
with get_tracer(__name__, __version__).start_as_current_span(
name="{cls}.{func}".format(cls=estimator_name, func=func.__name__)
):
return func(*args, **kwargs)
return wrapper
# Methods on which spans should be applied.
DEFAULT_METHODS = ["fit", "transform", "predict", "predict_proba"]
# Classes and their attributes which contain a list of tupled estimators
# through which we should walk recursively for estimators.
DEFAULT_NAMEDTUPLE_ATTRIBS = {
Pipeline: ["steps"],
FeatureUnion: ["transformer_list"],
}
# Classes and their attributes which contain an estimator or sequence of
# estimators through which we should walk recursively for estimators.
DEFAULT_ATTRIBS = {}
class SklearnInstrumentor:
"""Instrument a fitted sklearn model with opentelemetry spans.
Args:
methods (list): A list of method names on which to instrument a span.
This list of methods will be checked on all estimators in the model
hierarchy.
recurse_attribs (dict): A dictionary of ``BaseEstimator``-derived
sklearn classes as keys, with values being a list of attributes. Each
attribute represents either an estimator or list of estimators on
which to also implement spans. An example is
``RandomForestClassifier`` and its attribute ``estimators_``
recurse_namedtuple_attribs (dict): A dictionary of ``BaseEstimator``-
derived sklearn types as keys, with values being a list of
attribute names. Each attribute represents a list of 2-tuples in
which the first element is the estimator name, and the second
element is the estimator. Defaults include sklearn's ``Pipeline``
and its attribute ``steps``, and the ``FeatureUnion`` and its
attribute ``transformer_list``.
"""
def __init__(
self,
methods: "List[str]" = None,
recurse_attribs: "Dict[Type[BaseEstimator], List[str]]" = None,
recurse_namedtuple_attribs: "Dict[Type[BaseEstimator], List[str]]" = None,
):
self.methods = methods or DEFAULT_METHODS
self.recurse_attribs = recurse_attribs or DEFAULT_ATTRIBS
self.recurse_namedtuple_attribs = (
recurse_namedtuple_attribs or DEFAULT_NAMEDTUPLE_ATTRIBS
)
def instrument_estimator(self, estimator: "BaseEstimator"):
"""Instrument a fitted estimator and its hierarchy where configured.
Args:
estimator (BaseEstimator): A fitted ``sklearn`` estimator,
typically a ``Pipeline`` instance.
"""
if isinstance(estimator, tuple(self.recurse_namedtuple_attribs.keys())):
self._instrument_estimator_namedtuple(estimator=estimator)
if isinstance(estimator, tuple(self.recurse_attribs.keys())):
self._instrument_estimator_attribute(estimator=estimator)
for method_name in self.methods:
if hasattr(estimator, method_name):
setattr(
estimator,
method_name,
implement_spans(
getattr(estimator, method_name),
estimator.__class__.__name__,
),
)
def _instrument_estimator_attribute(self, estimator: "BaseEstimator"):
"""Instrument instance attributes which also contain estimators.
Examples include ``RandomForestClassifier`` and
``MultiOutputRegressor`` instances which have
``estimators_`` attributes.
Args:
estimator (BaseEstimator): A fitted ``sklearn`` estimator, with an
attribute which also contains an estimator or collection of
estimators.
"""
attribs = self.recurse_attribs.get(estimator.__class__, [])
for attrib in attribs:
attrib_value = getattr(estimator, attrib)
if attrib_value is None:
return
elif isinstance(attrib_value, Sequence):
for value in attrib_value:
self.instrument_estimator(estimator=value)
else:
self.instrument_estimator(estimator=attrib_value)
def _instrument_estimator_namedtuple(self, estimator: "BaseEstimator"):
"""Instrument attributes with (name, estimator) tupled components.
Examples include ``Pipeline`` and ``FeatureUnion`` instances which
have attributes ``steps`` and ``transformer_list``, respectively.
Args:
estimator: A fitted sklearn estimator, with an attribute which
contains a list of (name, estimator) tuples.
"""
attribs = self.recurse_namedtuple_attribs.get(estimator.__class__, [])
for attrib in attribs:
for _, est in getattr(estimator, attrib, []):
self.instrument_estimator(estimator=est)
The instrumentor recursively instruments the methods of each estimator, handling the special cases of estimators which have namedtuple sequences of estimators, or attributes holding estimators as defined by the user. The defaults configuration is to instrument the fit, transform, predict, and predict_proba methods of each estimator. The namedtuple default handles the Pipeline and FeatureUnion classes. The estimator attribute configuration defaults to an empty dictionary and should be provided by the end user.
Here is what an implementation might look like in a simple FastAPI server:
import logging
import pickle
import fastapi
import numpy as np
from opentelemetry import trace
from opentelemetry.exporter import jaeger
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchExportSpanProcessor
from opentelemetry.sdk.trace.export import ConsoleSpanExporter
from opentelemetry.sdk.trace.export import SimpleExportSpanProcessor
from sklearn.datasets import load_iris
from opentelemetry_sklearn.instrumentation.sklearn import SklearnInstrumentor
logging.basicConfig(level=logging.DEBUG)
# Configure opentelemetry
trace.set_tracer_provider(TracerProvider())
trace.get_tracer_provider().add_span_processor(
SimpleExportSpanProcessor(ConsoleSpanExporter())
)
jaeger_exporter = jaeger.JaegerSpanExporter(
service_name="fastapi-sklearn",
agent_host_name="localhost",
agent_port=6831,
)
trace.get_tracer_provider().add_span_processor(
BatchExportSpanProcessor(jaeger_exporter)
)
# Load the serialized machine learning model
sklearn_model = pickle.load(open("model.pkl", "rb"))
# Instrument the machine learning model
SklearnInstrumentor().instrument_estimator(sklearn_model)
X, y = load_iris(return_X_y=True)
app = fastapi.FastAPI()
@app.get("/predict")
async def predict():
"""Predict on random input features."""
rows = X.shape[0]
random_row = np.random.choice(rows, size=1)
prediction = sklearn_model.predict(X[random_row, :])
return prediction.tolist()
# Instrument the application
FastAPIInstrumentor.instrument_app(app)
We can run this server using the command
uvicorn myserver:app --reload
and spin up a Jaeger image using docker with the command
docker run -d -p 16686:16686 -p 6831:6831/udp jaegertracing/all-in-one
open http://localhost:16686
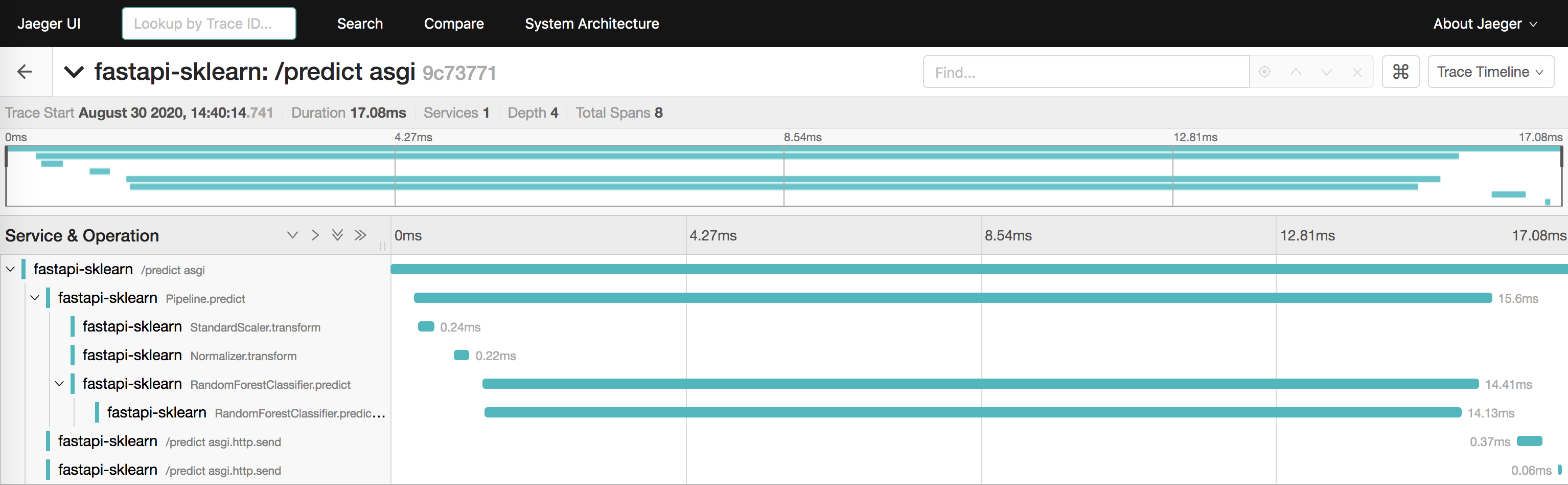
Now we can make a request to our FastAPI server,
curl http://localhost:8000/predict
and we should see spans not only for the web framework but also for the components of the machine learning model that we’ve instrumented.