flynn.gg
Christopher Flynn
Machine Learning
Systems Architect,
PhD Mathematician
Projects
Open Source
Blog
Résumé
GitHub
Blog
pypistats.org to GKE
2020-09-16 
I wrote and deployed pypistats.org first back in April 2018. It was deployed into an AWS Elastic Beanstalk environment, using a single t1.small node, and a single t1.small 10GB database; essentially as much free-tier infrastructure as I could get away with. The hosting cost was around $50-60 per month, after the 12-month initial account free tier expired.
I never shared the project outside of my personal blog, but it slowly grew to see over 3000 unique monthly users, and served several millions of requests per month, mostly through the JSON API. The shields.io service started using the API to back the python downloads badges, and an enthusiast wrote a pypistats API client package. People seemed to find the data useful.
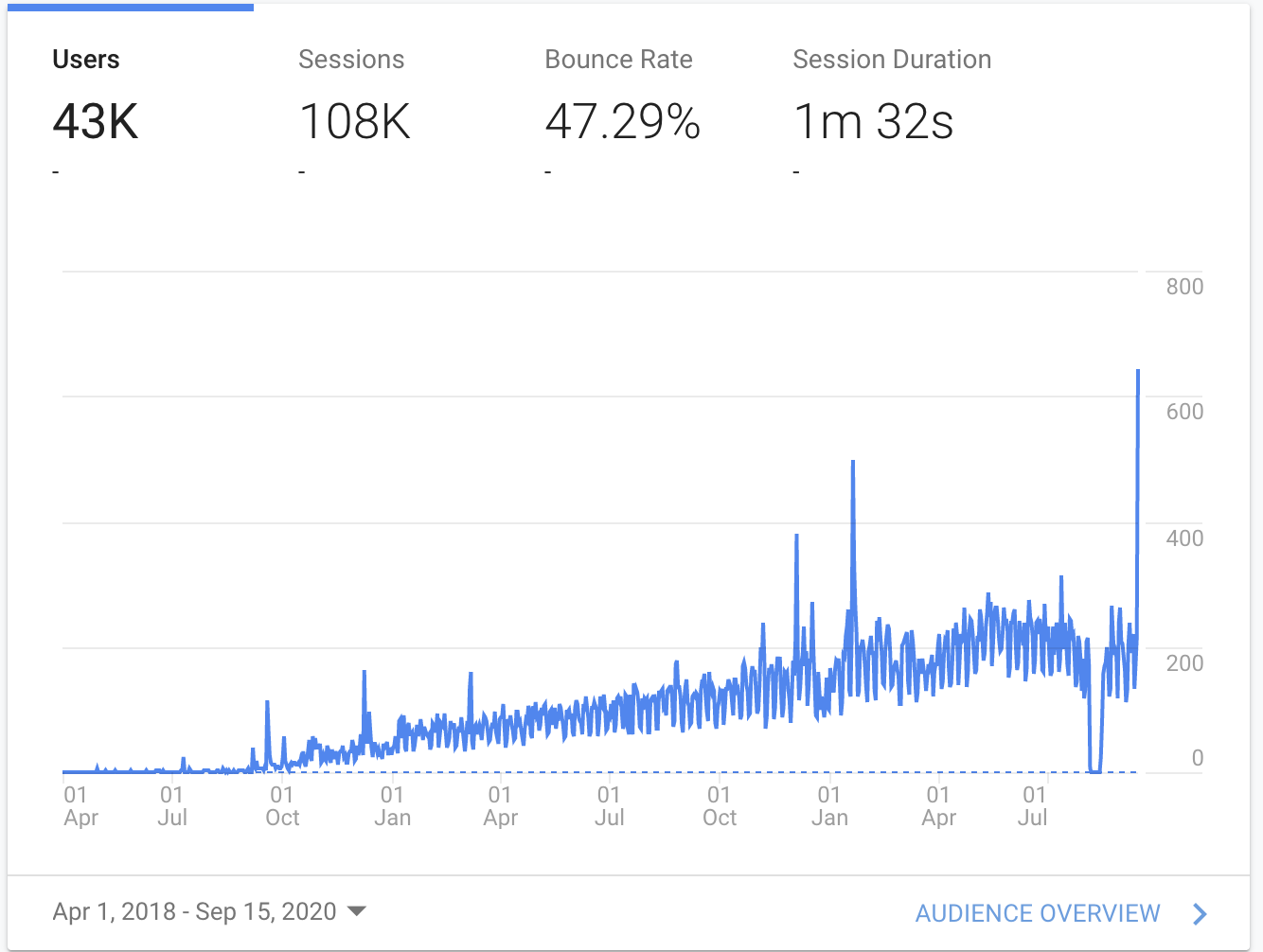
Recently, in July 2020, pypistats unexpectedly came offline and wouldn’t restart. As a result, I took the opportunity to rework the deployment of the application. The result was to migrate to Google hosted Kubernetes (with help from Rahul Basmangi). Since completing this migration, and making some more improvements, I think this is a good opportunity to reflect on troubles I experienced maintaining the app, why things got broken, and what I did to fix it.
Linehaul was fixed
Linehaul is the application which produces the records that end up in the Google BigQuery tables, from which pypistats data is sourced. Roughly one month after launching pypistats, in May 2018, it was discovered that linehaul was not recording a majority of download requests made to pypi. The cause was a memory leak which caused the server to flap, resulting in massive download data loss.
After it was fixed, the volume of data for a single day’s worth of downloads was roughly 6-10x what was previously being recorded. In a few weeks, the 10GB PostgreSQL instance pypistats was using filled up entirely. This broke the application, since with a full disk, no database logs could be written. This was also before storage autoscaling was introduced for RDS in June 2019.
To bring it back I bumped the storage from 10GB to 20GB and later a second time to 30GB, which exceeded the 120 day retention capacity needed. Lesson learned: Keep track of disk usage or enable storage autoscaling.
Scrapers
Pypistats originally offered a free unlimited JSON API to access the aggregated downloads for packages without having to access BigQuery. Unfortunately, for me, there were some curious individuals who decided to take advantage of this API, and attempt to download all the historical download data by making hundreds of thousands of requests for every single pypi package listed.
This created a problem with the infrastructure on which the application runs. The database especially, being on free tier t1.small, means that the instance has a limited amount of CPU credits, which regenerate slowly over time when depleted. With tons of high frequency access to the database, the CPU credits were consumed rapidly, leaving the database either slow or unable to respond to queries. This lead many requests to either respond after a long period of time or timeout completely at the load balancer. The ingestion task was taking hours instead of minutes to load a new batch of data.
This happened a few times and my (bad) solution was to return HTTP response code 503 to the historical data endpoints. Since the requests were being made alphabetically it was easy to watch the scrape-spammer’s logs until the alphabet of requests was exhausted. The endpoints were re-enabled after they went away.
Unfortunately, this happened again. And then it happened a third time. And it kept happening. And me, being unwilling to increase the hosting costs by using a more appropriately sized database machine, eventually just added rate limiting to the application. The rate limiting uses flask_limiter and sets some limits low enough that it can’t be abused.
from flask_limiter import Limiter
from flask_limiter.util import get_remote_address
from werkzeug.middleware.proxy_fix import ProxyFix
app = create_app()
# Rate limiting per IP/worker
app.wsgi_app = ProxyFix(app.wsgi_app)
limiter = Limiter(
app,
key_func=get_remote_address,
application_limits=["5 per second", "30 per minute"]
)
Lesson learned: Prevent free API abuse with rate limiting.
Inability to scale
The other difficulty of the deployment was that the application components ran as a singleton under supervisord. This meant that there was no ability to scale horizontally, because then there would be two beats and two celery workers running, in which they would perform duplicate ingestion operations every day. These components would need to be decoupled from the webserver before any horizontal scaling could be accomplished.
# The old supervisord.conf
[supervisord]
nodaemon=true
[program:redis]
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stdout
stderr_logfile_maxbytes=0
command=redis-server
[program:pypistats]
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stdout
stderr_logfile_maxbytes=0
command=bash -c "scripts/run_flask.sh"
[program:celery-worker]
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stdout
stderr_logfile_maxbytes=0
user=root
command=bash -c "scripts/run_celery.sh"
[program:celery-beat]
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stdout
stderr_logfile_maxbytes=0
command=bash -c "scripts/run_beat.sh"
Using Kubernetes allows for easier separation of these components. Each component gets its own deployment so that they are run independently from each other. Thus, the webserver can be scaled, and the beat/celery apps can be kept as singletons.
Lesson learned: Deploy application components with different scaling requirements separately.
Pinning (all) dependencies
In July 2020, pypistats’ deployment fell over and couldn’t be restarted. It fell over due to request spam, but it wasn’t able to be restarted because of how it was deployed to Elastic Beanstalk and how the Dockerfile was written.
The original deployment used a Dockerfile with supervisord to manage processes, with a single image managing a gunicorn server fronting a flask application, a celery worker, a beat scheduler, and a redis instance. The deployment would package the repository up with the Dockerfile and the Elastic Beanstalk EC2 instance would build the image and run it on the machine when it was deployed.
FROM python:3.6-slim
RUN apt-get update && apt-get install -y supervisor redis-server
RUN pip install pipenv==2018.10.13
ENV WORKON_HOME=/venv
ENV C_FORCE_ROOT="true"
WORKDIR /app
ADD Pipfile /app
ADD Pipfile.lock /app
RUN pipenv install
ADD . /app
EXPOSE 5000
CMD /usr/bin/supervisord
Above is the original Dockerfile. When Elastic Beanstalk deploys your application, if you don’t specify a docker image it builds from the Dockerfile provided in the deployment zip file. Note that in this Dockerfile doesn’t pin the redis-server requirement installed by apt. Redis had a major release version (6.0) in April 2020. With the application crashing in July, it was likely the first time it was rebuilt since prior to April, loading a newer version of redis. The celery version seemed to be incompatible with the new redis version and wouldn’t start up.
Lesson learned: Pin every dependency in an application including related services.
Migrating to GKE
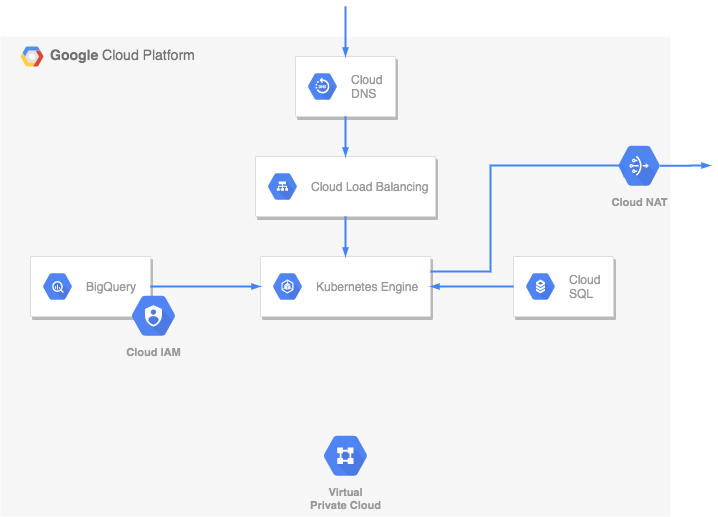
Using Kubernetes allowed separation of the components of the app. Beat and celery could be run independently of the webserver. The webserver on its own could then be scaled if needed. The webserver was also modified to be able to create tasks, so that I would be able to backfill easily when deploying to a fresh database, and if ingestion failed for any reason.
Using the public BigQuery tables meant just creating a service account. The PostgreSQL database uses Google Cloud SQL, where I provisioned a proper non-burstable instance so that there was no CPU bottleneck at the database. The rest of the infrastructure is standard ingress and VPC related networking. Since deploying, everything has been running smoothly.
Dev environment
To contibutors, setting up pypistats locally was really difficult. There were a few shell script files, but it was far from obvious how to spin up the app and its dependencies. Part of this migration included building a proper local environment using docker-compose.
A complete dev environment (except for BigQuery access) can be spun up with the make pypistats command after cloning. This command will build the docker container, launch the app components along with redis and PostgreSQL, and provide database seeds for all of the app’s own dependencies.