flynn.gg
Christopher Flynn
Machine Learning
Systems Architect,
PhD Mathematician
Projects
Open Source
Blog
Résumé
GitHub
Projects
Contents
Professional
- Real-time Machine Learning for Sports Betting
- Mobile Gaming Publisher Big Data Analytics Platform
- Mitosis Games Analytics Platform
- Black Diamond Casino
- Verizon Customer Churn
- Copy Correlation Signal Detection
Personal
Professional Projects
Real-time Machine Learning Systems for Sports Betting
At SimpleBet, I lead an engineering team building the software and infrastructure to enable real-time automated pricing of sports betting micro-markets using machine learning with Python and Kubernetes.
Our machine learning predictions are used in multiple products, including FanDuel PlayAction, DraftKings Sportsbook, Playbook.game, and YES Network Pick N Play.
Mobile Gaming Publisher Big Data Analytics Platform


At Tilting Point I rebuilt the data analytics platform. I migrated the entire data pipeline from Jenkins to an Apache Airflow cluster. Daily data ingestion tasks were handled by PySpark Databricks jobs. Analytics tables were migrated from standard parquet tables ingested in batch to Delta Lake tables ingested using Spark Structured Streaming.
I also migrated the backend from a serverless, manually controlled AWS API Gateway to fully automated live server environment with Golang, saving thousands in monthly operational costs. The backend was instrumented with Prometheus and Grafana for monitoring, using Locust for load testing, and Jenkins for CI/CD automation. All of these solutions were deployed with Docker in AWS. The logging solution was the ELK (Elasticsearch, Logstash, Kibana) stack.
Mitosis Games Analytics Platform

At Mitosis Games, I built the analytics backend while the team built their first title, Magic Meadow, a story-driven fantasy-themed match-3 adventure.
Within AWS, I architected a data analytics pipeline using Kinesis Firehose to consume events fired from out client SDK to our API, with Redshift as a data warehouse. A separate AWS RDS PostgreSQL database acted as a datastore for aggregate analytics data. This database backed an analytics dashboard I built using Python Flask and plotly.js, deployed on Elastic Beanstalk. Automated tasks and other cron operations were performed using Python and Celery deployed to EC2 with a Redis Elasticache broker.
Black Diamond Casino

At Zynga I worked as a Data Scientist with the Rising Tide Games team. Our studio produced a slot machine mobile app called Black Diamond Casino. The app performed well with peak metrics of roughly 250,000 daily active users, #15 top-grossing casino (#53 top-grossing overall) on iOS, #17 top-grossing casino (#66 top-grossing overall) on Android in mid-2016.
My responsibilities were mainly product analytics, including generating automated reports and visualizations on product data and experiments using Amazon Redshift and Python. I developed mathematical models for retention, daily cohorted lifetime value forecasting of monetizers, late conversion, and churn. I created several metrics to measure aspects of player behavior, game interest, and monetization habits.
I collaborated with engineers and artists to develop and optimize in-game features, such as rewarded advertisements and achievements. I also performed live operations on the app such as content releases, A/B testing, and sale/promo execution.
Verizon Customer Churn Model

As a Data Science Intern at Verizon Wireless, I developed a subscriber churn prediction model based on online support chat conversation contents using natural language processing and machine learning. The model used several machine learning techniques including Naive Bayes, Logistic Regression, and Random Forests. Feature selection was performed using Information Gain. The models were evaluated using F-score with an emphasis on recall performance.
Copy Correlation Signal Detection

MIT Lincoln Lab hosted me as an intern in their Advanced Sensor Techniques group for three summers while I was working on my PhD. I worked with engineers and mathematicians to evaluate the performance of an estimation algorithm they created. The estimator is known as Copy Correlation, and its purpose is to approximate the direction of arrival of an incoming signal on an antenna array.
I completed derivations to identify the theoretical mean squared error performance of the estimator, using linear algebra and complex-valued probability distributions. The derivations were verified by Monte Carlo simulations coded in MATLAB.
The results are published in conference papers here and here.
Personal Projects
PyPIStats
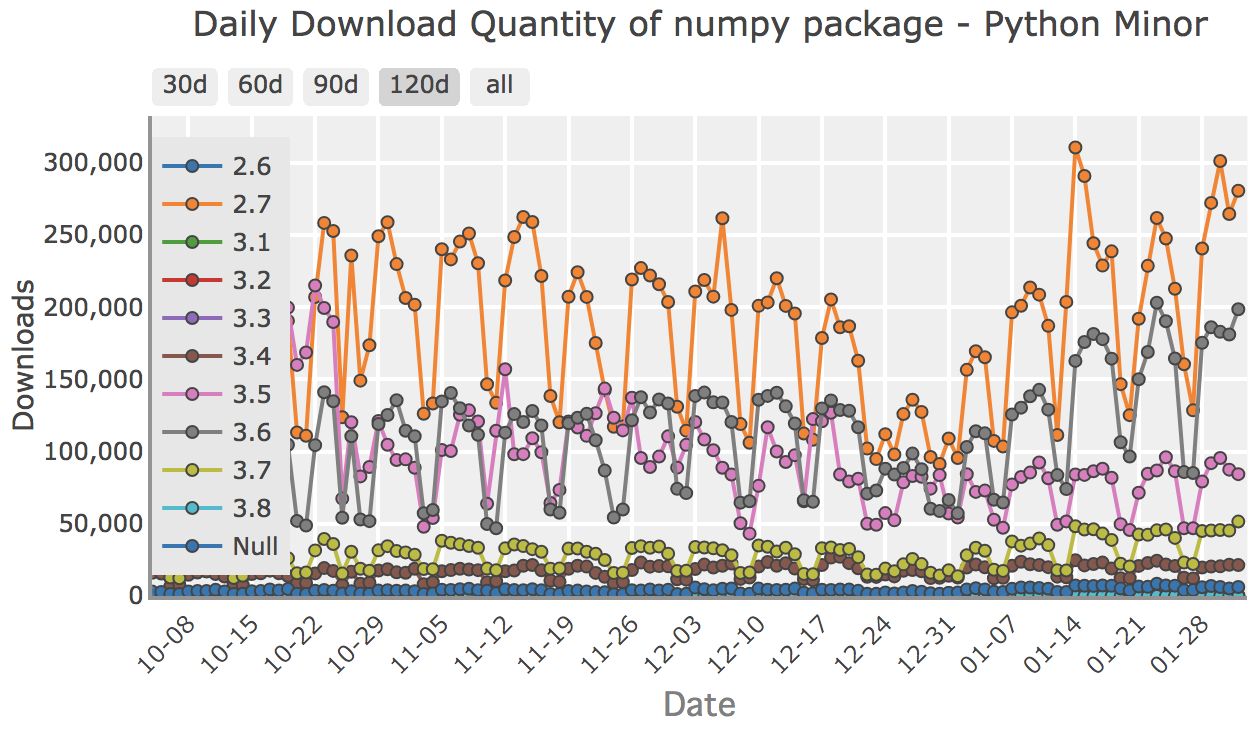
A simple dashboard website and JSON API for providing aggregate download stats for python packages from the Python Package Index (PyPI). The website is built in python using Flask with Celery executing ingestion tasks, Celery-beat as a task scheduler, and redis as a message queue/task broker. Visualizations use the plotly.js library. The site supports GitHub OAuth to allow users to personally track packages. The website is deployed to a Kubernetes cluster on Google Cloud’s GKE.